
今回は、データ分析の総まとめとしてヒストグラム、箱ひげ図、散布図の読み取りに関する問題を、直近の共通テストのエッセンスを抽出した問題を通して徹底解説してきます。グラフから四分位数や中央値などを読み取るのが苦手という人や、問題を解くコツが知りたいという人は、ぜひ最後までチェックしてみてください!
- ヒストグラムや箱ひげ図、散布図の読み取りが苦手な人
- データ分析で頻出の用語をわかりやすく理解したい人
- データ分析分野を解くコツが知りたい人
- 共通テスト対策がしたい人
- 受験対策・定期テスト対策がしたい人

高校数学の勉強のコツ、日常生活に潜む数学をゆる~く解説した
note記事も更新中!
ぺんきち|高校数学の図解ノート
数学 / 理科(物理・化学・生物・地学)
本記事の要点
本記事では、データ分析の総まとめとして図表の読み取りや計算問題の解き方について解説していきますが、まずはじめに本記事の結論をお伝えします。
☆重要Point☆
・用語や図表は計算方法だけでなく意味もしっかり理解しよう。
・図表の読み取りは、四分位数を確認せよ!
上記結論をもとに、データ分析で頻出の問題や必須の考え方について、共通テスト問題を通して理解を深めていきましょう!
【問題&解説】データ分析
問題に入る前に基本的な用語や図表(ヒストグラム、箱ひげ図、散布図)の見方を復習しておきたい人は、はじめに講義1_必須用語の確認から読むのがおすすめです。
【問題1】ヒストグラム(中央値、最頻値)
下図は、50人で校内マラソンをしたときのベストタイムを2000年より前(Aのヒストグラム)と2000年以降(Bのヒストグラム)で整理したものである。ただし、ヒストグラムの各階級の区間は、左側の数値を含み、右側の数値を含まない。
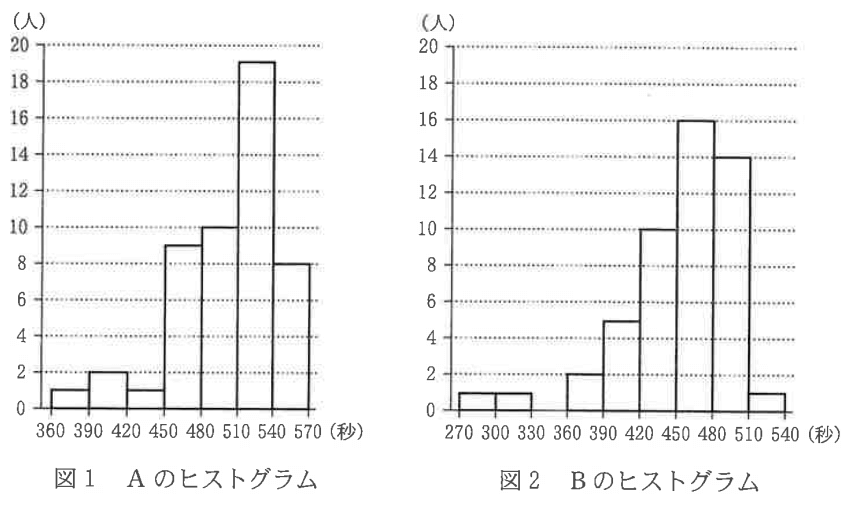
(1)Aの最頻値を求めよ。
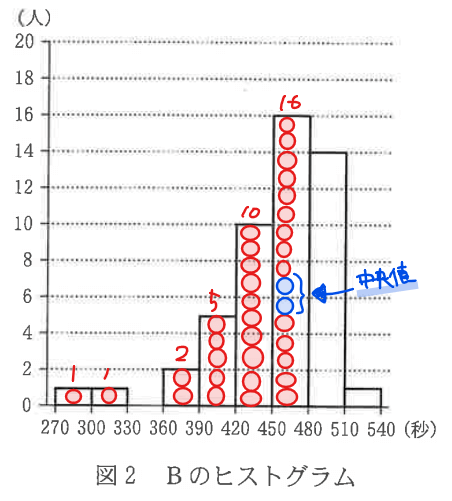
(2)Bの中央値が含まれる階級を答えよ。
[2024年度共通テスト 改題]
最頻値とは、最も人数が多い階級値のことなので、ヒストグラムから一番人が多い区間は、\(\small 510~540\)秒で19人。階級値は階級の区間のど真ん中の値なので、\(\small \displaystyle \frac{510+540}{2}=\color{red}{525}\)秒…【答】。
全データの個数(人数)は50人なので、中央値(ど真ん中の人)は、25番目と26番目の間になる。よって、小さい順に25番目と26番目のデータが含まれる階級を考えればよいので、下図から、450以上480未満の階級…【答】に含まれる。
【問題2】ヒストグラム(四分位数、四分位範囲)
下図は、都道府県庁所在地および政令指定都市(全52市)におけるかば焼きの支出金額を表したヒストグラムである。なお、ヒストグラムの各階級の区間は、左側の数値を含み、右側の数値を含まない。
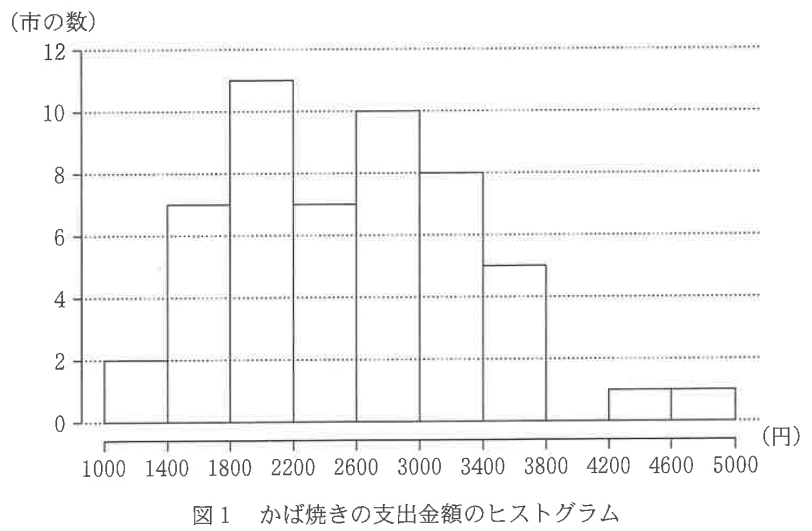
このヒストグラムから、第1四分位数が含まれる階級は \(\small \bf{\bbox[3px, border: 2px double black]{ ア }}\)、 第3四分位数が含まれる階級は \(\small \bf{\bbox[3px, border: 2px double black]{ イ }}\)、四分位範囲は \(\small \bf{\bbox[3px, border: 2px double black]{ ウ }}\)である。
\(\small \bf{\bbox[3px, border: 2px double black]{ ア }}\)、\(\small \bf{\bbox[3px, border: 2px double black]{ イ }}\)の選択肢
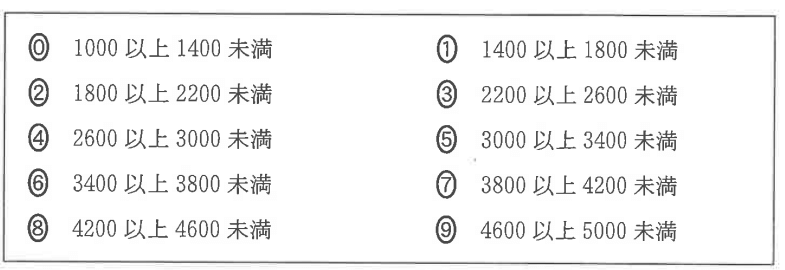
\(\small \bf{\bbox[3px, border: 2px double black]{ ウ }}\)の選択肢

[2023年度共通テスト 改題]
全体のデータ数が52であることから、第1四分位数(\(\small Q_{1}\))、第3四分位数(\(\small Q_{3}\))、四分位範囲(\(\small =Q_{3}-Q_{1}\))の関係は下図の通り。
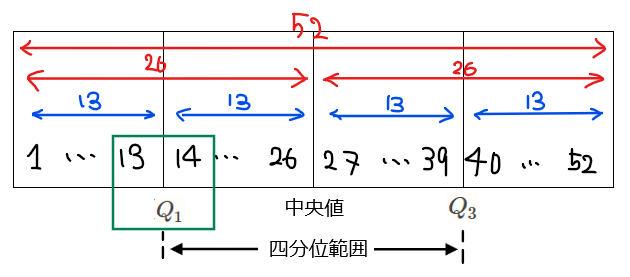
第1四分位数は、下から13番目と14番目のデータの間なので、ヒストグラムから1800~2200の階級に含まれる。よって、ア:②…【答】。
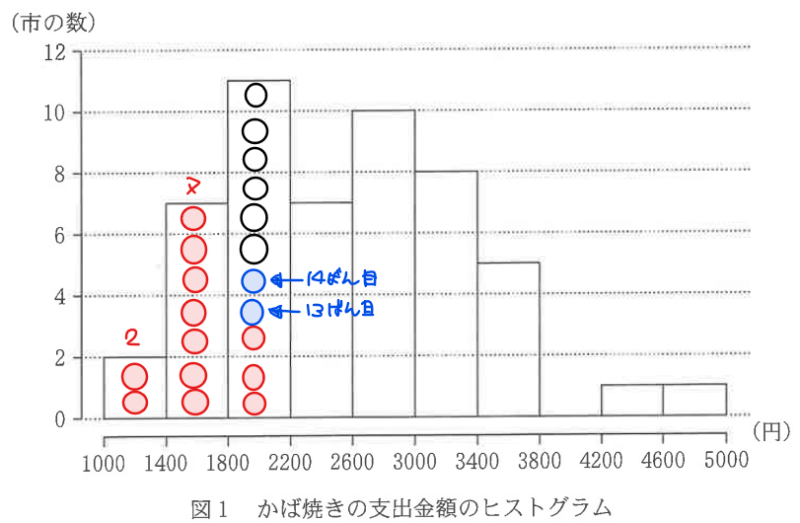
同様に、第3四分位数は、上から13番目と14番目のデータの間(下から39番目と40番目の間と考えてもよいが数えるのが大変なので上からの方が楽)なので、3000~3400の階級に含まれる。よって、イ:⑤…【答】。
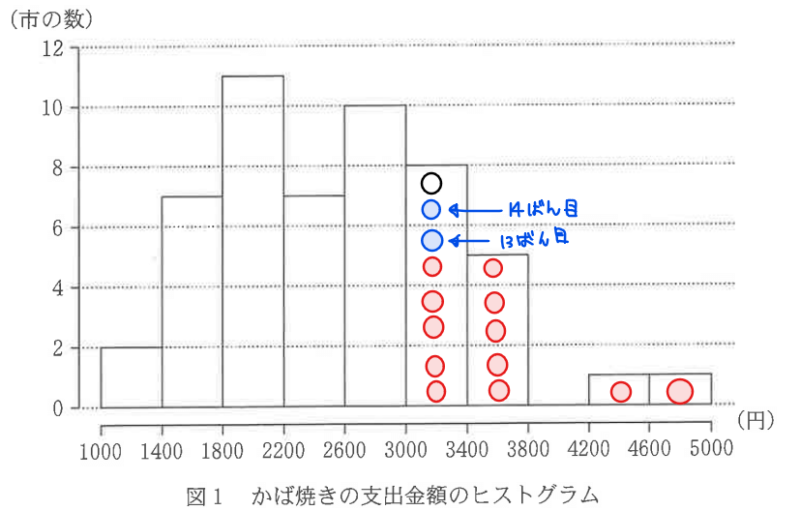
四分位範囲は、\(\small Q_{3}-Q_{1}\)で計算できる。でも、\(\small Q_{1}\)の具体的な値は、下位13番目の市の支出額と14番目の市の支出額が分からないと計算できない(\(\small Q_{3}\)も同様の理由で計算できない)。
一方で、下位13番目と14番目が属する階級は分かっているので、最大でこのくらいという値と、最低でもこのくらいという値の範囲までなら計算ができそう。選択肢を見ても範囲を聞かれているので計算していこう。
\(\small Q_{1}\)が属する階級は、\(\small 1800≦Q_{1}<2200\)(問題文から階級の左側を含み、右側を含まない点に注意)、\(\small Q_{3}\)が属する階級は、\(\small 3000≦Q_{3}<3400\)なので、\(\small Q_{3}-Q_{1}\)は、
\begin{cases}
\small -2200 <-Q_{1}≦-1800\\
\small \quad 3000≦Q_{3}<3400\\
\end{cases}
を足し算することで、\(\small 800<Q_{3}-Q_{1}<1600\)。
よって、800より大きく1600より小さい(ウ:①)…【答】。
●補足:四分範囲の計算の別解
解答では不等式を利用して説明したが、共通テストでは選択肢が与えられており、細かい端点を含むか否かにはそれほど気を付けなくてよいので、サクッと計算したければ、例えば最大になるのは、\(\small Q_{3}\)の最大値3400から\(\small Q_{1}\)の最小値1800を引いた1600、逆に最小になるのは、\(\small Q_{3}\)の最小値3000から\(\small Q_{1}\)の最大値2200を引いた800と求めてもよい。
【問題3】箱ひげ図の読み取り
以下の箱ひげ図は、それぞれ地域E(全19市)と地域W(全39市)のかば焼きの支出金額を表している。この箱ひげ図から読み取れることとてて正しいものを次のア~オからすべて選べ。
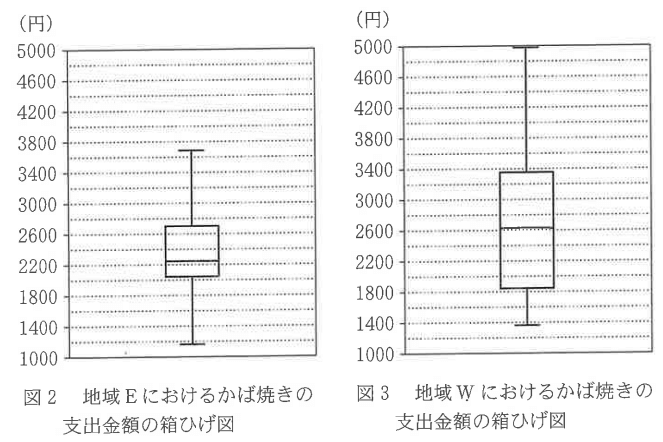
ア:地域Eにおいて、小さい方から5番目は2000以下である。
イ:地域Eと地域Wの範囲は等しい。
ウ:中央値は、地域Eより地域Wの方が大きい。
エ:2600未満の市の割合は、地域Eより地域Wの方が大きい。
オ:地域Eの2000以下の市の割合と地域Wの3400以上の市の割合はほぼ同じである。
[2023年度共通テスト 改題]
選択肢アを考えるにあたっては、地域Eの小さい方から5番目の市が箱ひげ図のどのあたりにいるかがポイント。
地域Eは全19市あるので、中央値をとるデータは小さい方から10番目、第1四分位数をとるデータは、小さい方から5番目である。
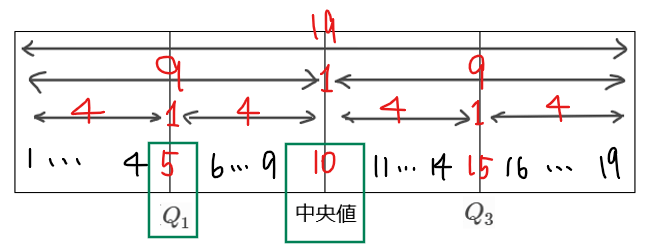
つまり、選択肢アにある「小さい方から5番目は2000以下」=「第1四分位数は2000以下」ということになるが、図からは2000より若干大きいことが分かるので、不適。
選択肢イについて、「範囲=最大値-最小値」なのでそれぞれ計算してもよいが、明らかに地域Wの方が範囲が大きい値になるので、不適。
選択肢ウについて、中央値は箱ひげ図の下図の部分なので、図から地域Wの方が大きいことが分かる。よって、正しい。
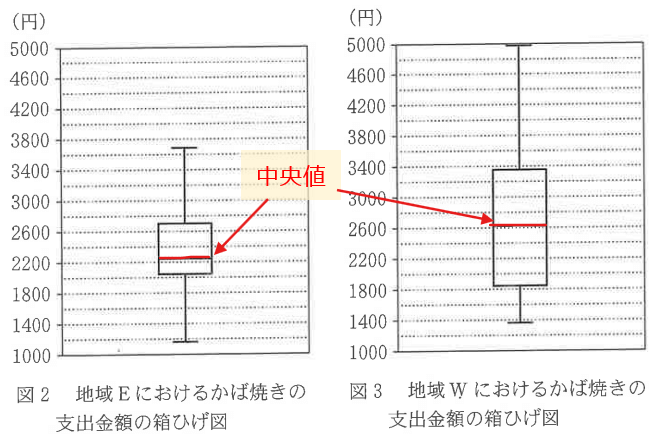
選択肢エについて、2600未満の市の割合をそれぞれ見ると、地域Eはおおよそ第3四分位数くらいなので、下位75%の市が含まれており、地域Wはおおよそ中央値なので下位50%の市が含まれている。
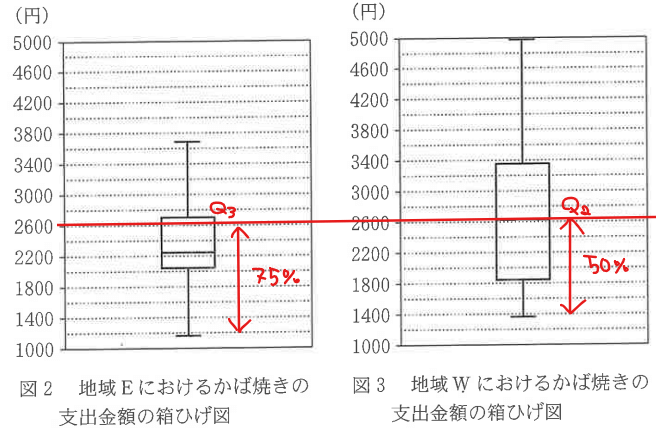
よって、2600未満の市の割合は、地域Eの方が大きいため選択肢エは不適。
選択肢オも同様に考えると地域Eの2000以下の市の割合は第1四分位数とほぼ等しいので約25%程度で、地域Wの3400以上の市の割合は第3四分位数とほぼ等しいので25%程度となることから、正しい。
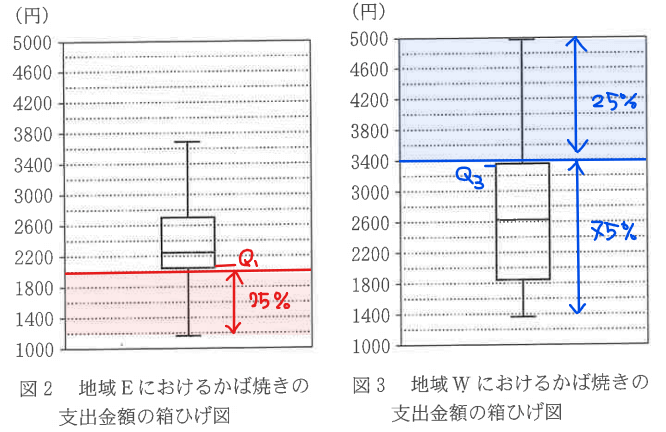
よって、正しい解答はウ、オ…【答】。
【問題4】箱ひげ図とヒストグラム
下図は、1985年と1995年の1次産業、2次産業、3次産業に従事する就業者数の割合を表した箱ひげ図である。各年代の箱ひげ図は上から順に1次産業、2次産業、3次産業のものである。
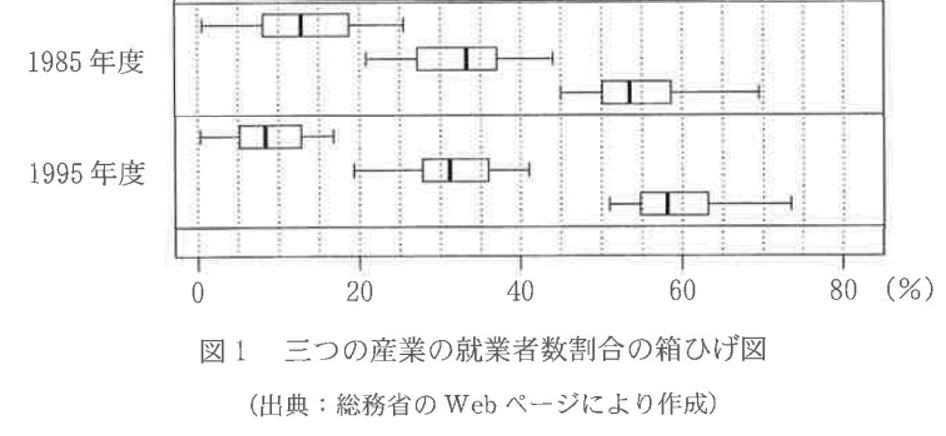
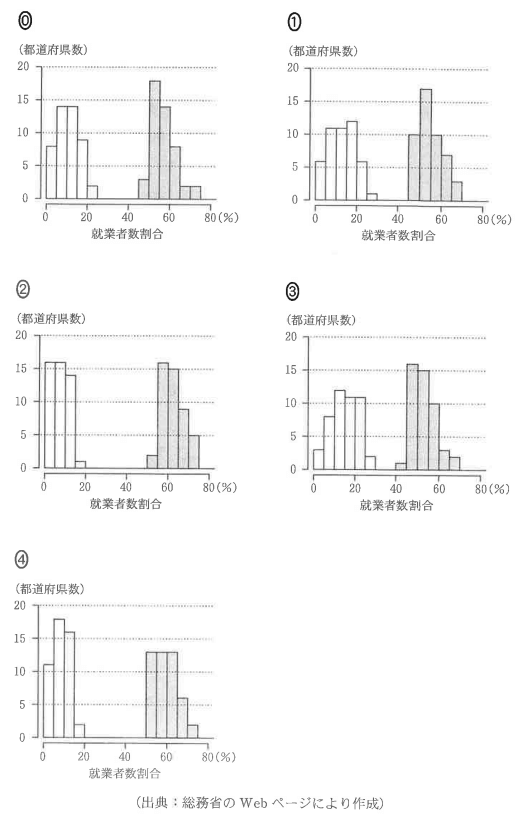
このとき、各年代における47都道府県別の1次産業と3次産業の就業者数割合をヒストグラムにまとめたものとして正しいものを、それぞれ1つずつ選べ。
[2021年度共通テスト 改題]
1985年のヒストグラムがどれになるかから考えていく。1次産業と3次産業のヒストグラムなので、箱ひげ図でいうと、一番上と一番下のものを見て考えていけばOK。
まずは全体の範囲からざっくりと確認。1次産業は最小値が0~5の階級に、最大値が25~30の階級にあるので、この時点で25~30の階級にデータが1つもない⓪、②、④は不適。
2択の絞り込みのために両者の大きな違いを見てみると、40~45の階級のデータ有無があるが、箱ひげ図で確認すると最小値がちょうど45あたりなので、①と考えてもよいが、少し不安なので他の材料でも確認しておくのが無難。
細かい情報としては、第1四分位数、中央値、第3四分位数を見ておけばよいだろう。
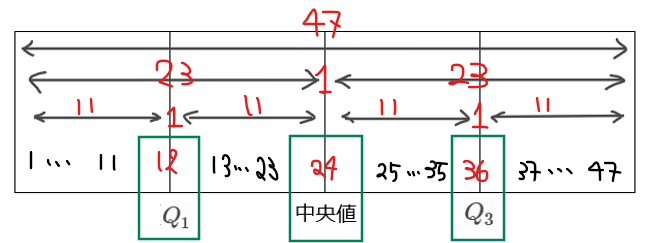
上図から第1四分位数は下位12番目のデータ、中央値は下位24番目のデータ、第3四分位数は下位36番目のデータであることが分かる。
あとは、それぞれが含まれる階級を箱ひげ図から確認していく。例えば、1次産業であれば、第1四分位数は5~10の階級にあるので、この階級に12番目のデータが含まれていればOK。
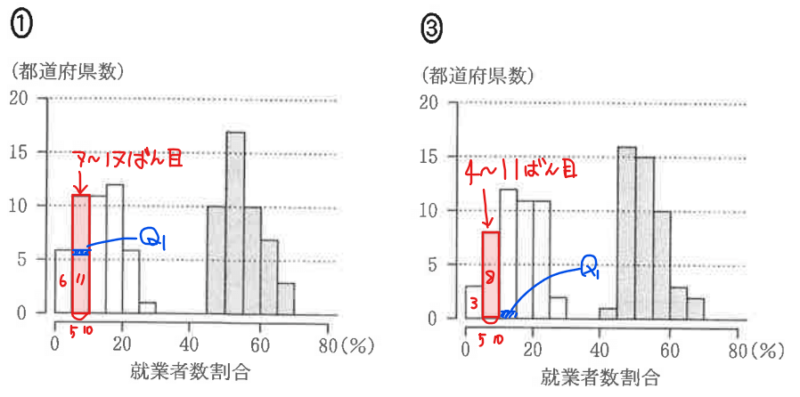
実際に確認すると、上図のように、①は5~10の階級に第1四分位数が含まれているが、③は10~15の階級に含まれているため、③は不適。
よって、1985年の箱ひげ図を表すヒストグラムとしては、①が正しい…【答】。
同様に1995年のヒストグラムについても考える。1次産業の最大値が15~20の階級にあることから、②か④に絞られる(それ以外は1次産業の最大値が20を超えているため不適)。
2つのヒストグラムで大きく違いがありそうな3次産業の四分位数が含まれる階級を見ていこう。
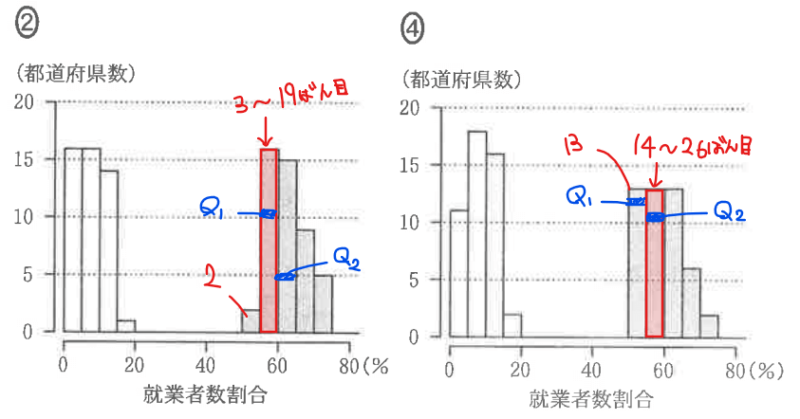
第1四分位数は、箱ひげ図からちょうど55くらい(若干50~55の階級に含まれていそう)。ヒストグラムで12番目(=\(\small Q_{1}\))のデータが含まれる階級を見ると、②が「55~60」、④が「50~55」なのでまだ明確に判別できない。
なので、続いて中央値を確認しておくと、中央値は24番目のデータだったので、24番目が含まれる階級は②が「60~65」、④が「55~60」となっており、箱ひげ図を見ると中央値は明らかに55~60の階級に含まれるので、④が正しい…【答】ことが分かる。
【問題5】箱ひげ図、ヒストグラムと散布図
下図は、学習者数が5000人以上の国と地域29か国を対象に、2009年度における教育機関1機関あたりの学習者数の箱ひげ図と、同年における教員1人あたりの学習者数のヒストグラムである。
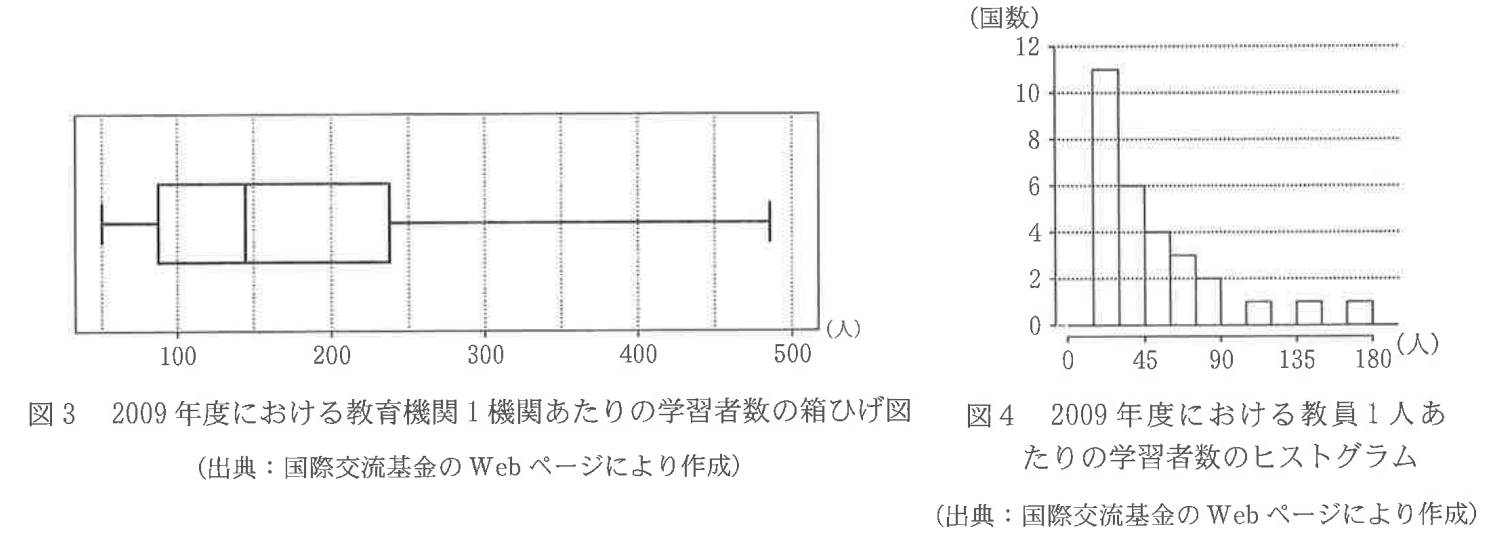
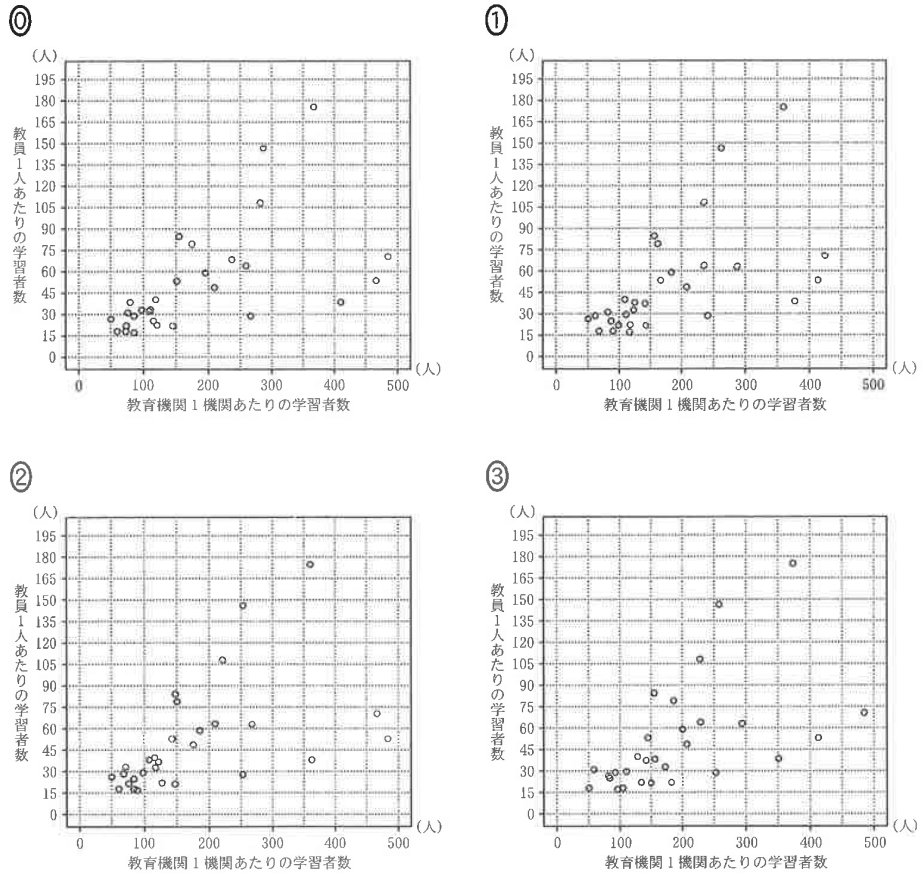
このグラフをもとに横軸に「教育機関1機関あたりの学習者数」、縦軸に「教員1人当たりの学習者数」をとった散布図を次の選択肢から1つ選べ。ただし、これらの散布図には、完全に重なっている点はないものとする。
[2022年度共通テスト 改題]
ヒストグラムを見て各階級にデータが何個あるかを数えてもよいが、意外とどの選択肢も合致しており効果的に絞り込めないので、箱ひげ図の四分位数から絞り込みをしていく。
全体のデータ数が29個あるので第1四分位数は下位7番目と8番目の間、中央値は下位15番目のデータとなる。
箱ひげ図から第1四分位数は0~100の階級にあるので、0~100の階級までの中にデータが最低でも7個はあることになる(下図参照)。
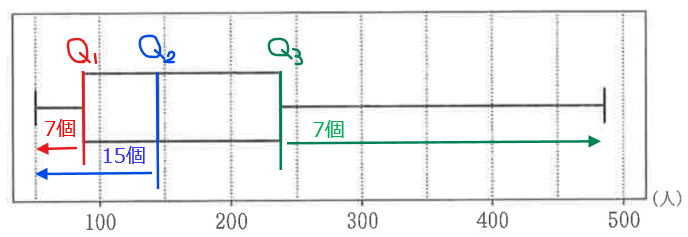
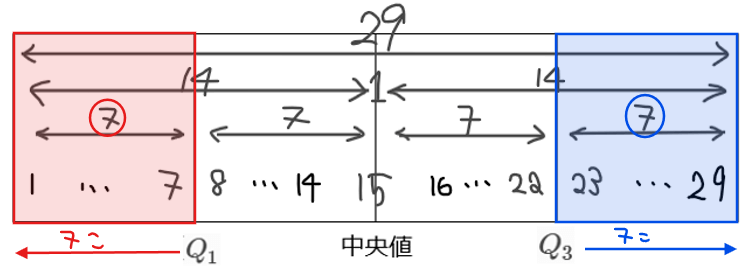
このことを踏まえると、③は0~100の階級にデータが6個しかないことから、③は不適(7個目のデータが100~150の階級に含まれることになるので、7個目と8個目のデータの間にある\(\small Q_{1}\)も100~150の階級にあることになり箱ひげ図に矛盾)。
次に、箱ひげ図の最大値が450~500の階級にあることから、①は不適。さらに、第3四分位数が200~250の階級にあることから、第3四分位数以上のデータは7個になるはずだが、⓪は8個のデータがあるため不適(上位7番目と8番目の平均が\(\small Q_{3}\)になるので、⓪の\(\small Q_{3}\)は250を超えてしまう)。
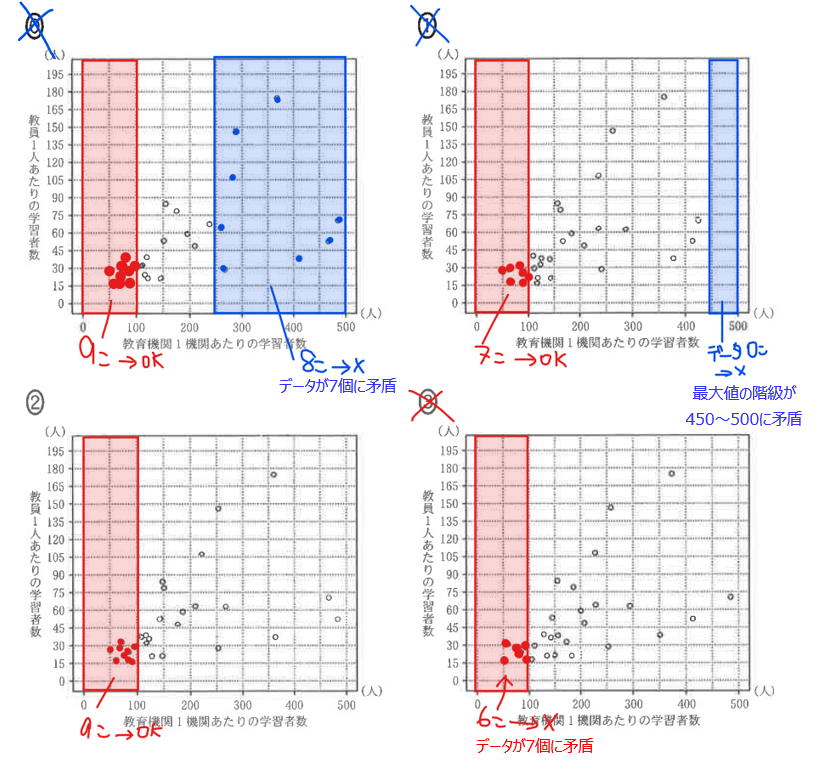
よって、②が答え…【答】(四分位数や最大最小値が箱ひげ図とも矛盾しない)。
【問題6】共分散と散布図
下図は、学習者数が5000人以上の国と地域29か国を対象に、生徒数(以下\(\small S\))と教員数(以下\(\small T\))のそれぞれの平均値、標準偏差と\(\small S\)と\(\small T\)の共分散をまとめた表である。このとき次の設問に答えよ。

(1)\(\small S\)と\(\small T\)の相関係数を小数点以下第2位までで求めよ。ただし、表1の数値は四捨五入していない正確な値であるものとする。
(2)横軸に\(\small S\)、縦軸に\(\small T\)をとった散布図として最も適当なものを1つ選べ。なお、これらの散布図には、完全に重なっている点はないものとする。
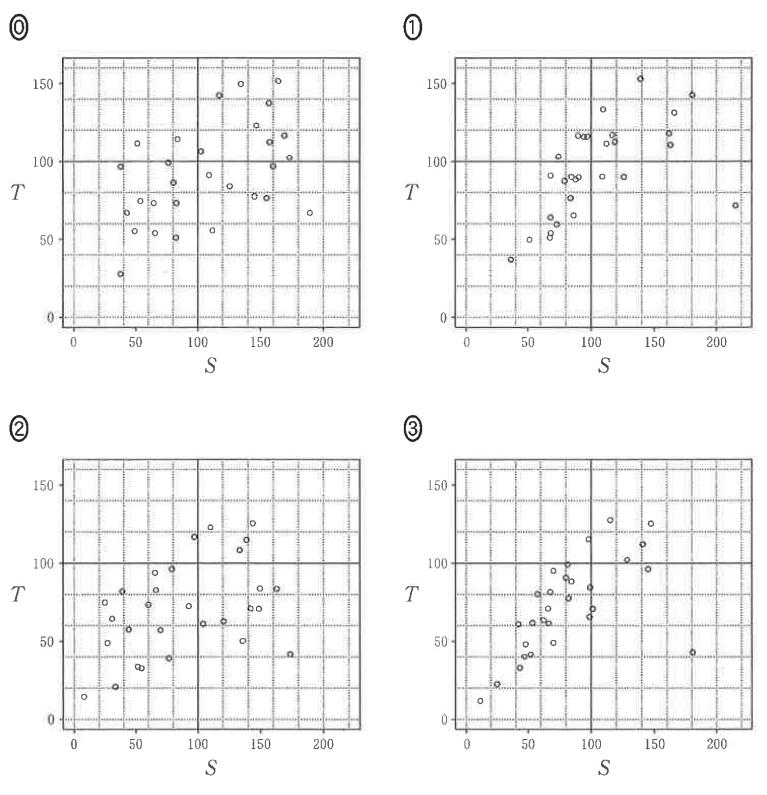
[2022年度共通テスト 改題]
\(\small S、T\)の共分散を\(\small \sigma_{ST}\)、\(\small S\)の標準偏差を\(\small \sqrt{\sigma_{S}}\)、\(\small T\)の標準偏差を\(\small \sqrt{\sigma_{T}}\)とすると相関係数\(\small r\)は、
$$\small r=\frac{\sigma_{ST}}{\sqrt{\sigma_{S}}\sqrt{\sigma_{T}}}$$
●補足:相関係数の公式について
相関係数の公式を日本語的で書くならば
$$\small \displaystyle \mathbf{相関係数}=\frac{S、T\mathbf{の共分散}}{S\mathbf{の標準偏差}\times T\mathbf{の標準偏差}}$$
解説に登場する\(\small \sigma\)はシグマと読みます(数列の和に出てくるギリシャ文字\(\small \sum\)の小文字ですね)。
標準偏差は分散の平方根なので、通常は分散を\(\small \sigma\)で表し、標準偏差は\(\small \sqrt{\sigma}\)で表します。
参考書によっては共分散も標準偏差もどちらも同じ記号\(\small s\)を使ってたりして分かりにくいので、本記事ではこの表記にしています。
よって、
\begin{split}
\small r & \small =\frac{735.3}{39.3 \times 29.9}\\
\small &\small =0.625\cdots
\end{split}
より、0.63…【答】と求まる。
(1)で求めた相関係数は、0.5を超えていることから「強めの相関あり」となるので、選択肢は①か③に絞られる。
あとは表にある情報で使えそうなのは平均値くらい(標準偏差や共分散は図形的な意味と紐づけが難しい)なので、ざっくりと平均があっていそうかを見比べていく。
\(\small S\)の平均値がだいたい80くらいなので、80以下と80以上のデータ個数をそれぞれ確認してみると、①は80以下のデータ個数が9個、80以上のデータが20個で、③は80以下のデータは16個、80以上のデータは13個であることから、①は感覚的に80以上のデータが多すぎて平均も80を越えそうだ(厳密に計算していないと分からないですが…)。
よって、③…【答】を選択するのが妥当でしょう。
●補足:答えの絞り込みについて
・平均値との比較は\(\small T\)の値から考えてもOKです。
・平均値は中央値とは異なり平均値前後でデータの個数が半分に分かれるわけではないですが、全体的なバランスもみて答えを選択してく感じになるでしょう(個人的には良問とは言えないですが、共通テストではたまにこういう問題も出てきます)。
【徹底解説】データ分析の攻略法
【講義1】必須用語の確認
まずは、データ分析で頻出となる用語の意味について復習しておきます。ここにある用語は、ただ丸暗記するだけではなく、しっかりと意味まで理解しましょう。
平均値
全データの値を均等にならしたときの値。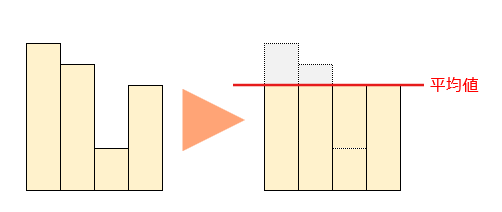
例)10人がテストをして9人が0点、1人だけ100点だった場合、テストの平均点は100(点)÷10(人)=10点となり、実態ほぼ0点という状況とかけ離れてしまう。
中央値
データを小さい順(または大きい順)に並べたときにちょうど真ん中のデータの値。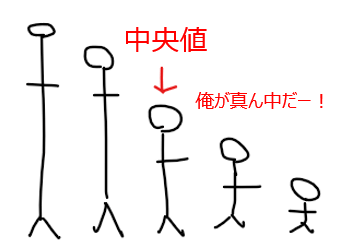
データが偶数個の場合は、ちょうど真ん中に該当するデータがないため、中央前後のデータの平均値が中央値となる。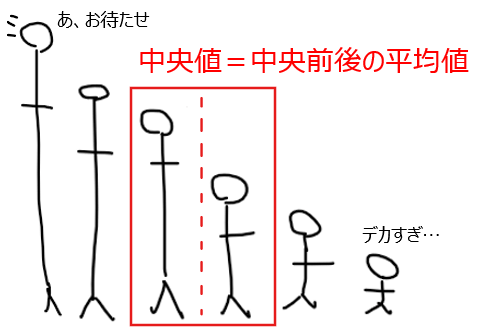
ヒストグラムと階級値・最頻値
ヒストグラムとは下図のような棒グラフのこと。
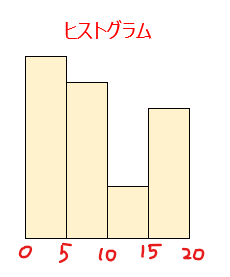
棒の幅を階級とよび、棒の高さがデータ数を表します。また、階級の平均値を階級値といいます。
たとえば、階級の幅が10~15の場合の階級値は \(\small \displaystyle \frac{10+15}{2}=\color{#ef5350}{12.5}\)になります。
あと、一番データ数が多い値を最頻値といいます。階級ごとに整理されたデータの場合は、データ数が最も多い階級の階級値が最頻値になります。たとえば、冒頭のヒストグラムであれば、データ数が一番多いのは、棒の高さが一番高い0~5の階級ですから、最頻値は、\(\small \displaystyle \frac{0+5}{2}=\color{#ef5350}{2.5}\)になります。
四分位数
データの個数を4分割したときに、小さい方から25%(半分の半分)に該当するデータが第1四分位数(\(\small Q_{1}\))、小さい方から75%(大きい方から25%)に該当するデータが第3四分位数。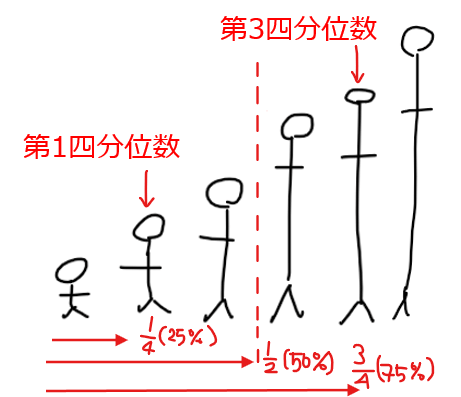
ちなみに、第2四分位数(\(\small Q_{2}\))は小さい方から50%に該当するデータなので中央値のこと。
また、(第3四分位数)ー(第1四分位数)= 四分位範囲と呼びます。
四分位数の求め方のコツは講義2で詳しく解説します。
箱ひげ図
四分位数を図式化したもの。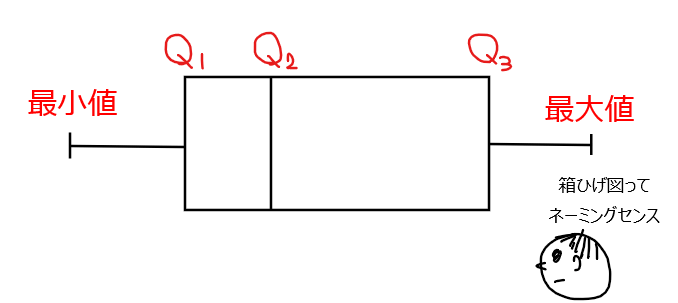
ちなみに、箱ひげ図は通常は上図のように横向きですが、縦向きに表現することもあります。
分散
各データ値と平均値の差の2乗の平均のこと。
数式にするとこんな感じ。
●分散の公式
$$\small \displaystyle \sigma=\frac{\sum \limits_{i=1}^n(x_i-m)^2}{n}$$
\(\small \sigma\):分散、\(\small n\):データの個数、\(\small x_i\):各データの値、\(\small m\):平均値
式自体は覚えなくってOK。具体例で求め方を覚えるのがおすすめ。
●具体例
Aさん、Bさん、Cさんの3人の身長がそれぞれ160cm、173cm、165cmのとき、3人の身長の分散を求めてみよう。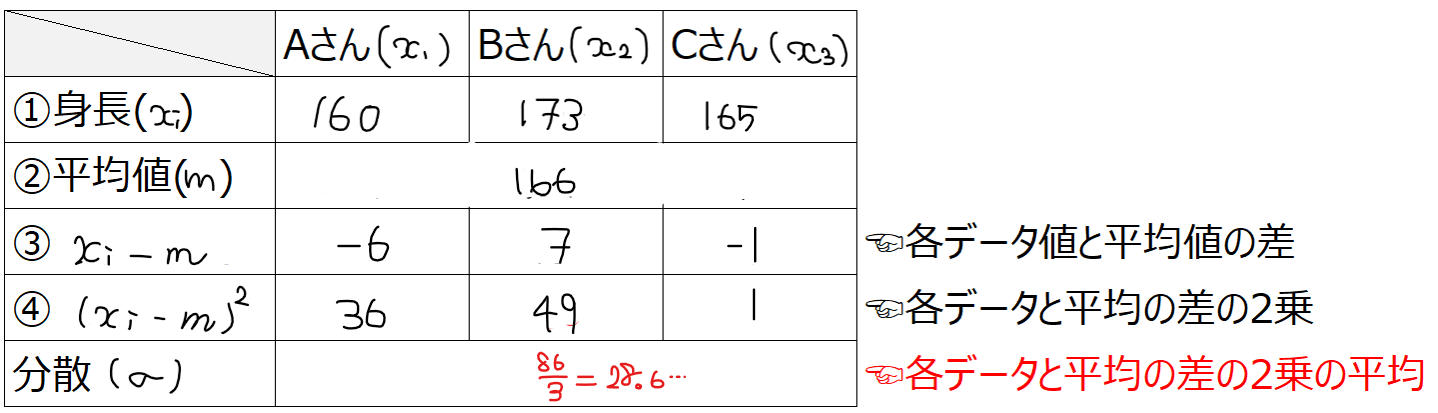
上図のように、まず3人の身長の平均値を求めます(②)。次に、それぞれの身長から平均を引いた値を計算(③)して、2乗します(④)。最後に、2乗した値の平均を求めると分散になります。
このステップを一言でいうと「各データ値と平均値の差の2乗の平均」になります。
改めて見ると、なんとなく理解できた気になったんじゃないでしょうか?少なくとも複雑な式を覚えるよりも簡単ですね。
標準偏差
分散のルートをとった値。簡単ですね。
先程の例題であれば、分散が\(\small \displaystyle \frac{86}{3}\)なので、標準偏差は\(\small \displaystyle \frac{\sqrt{258}}{3}≒5.35\)です。
●豆知識:分散や標準偏差ができたワケ(物語仕立て)
*これはフィクションです。
とある日のピタゴリア王国…
国王:データのばらつきを数学的に定義しておいて~(よろしく)。
召使:各データの平均からの差(ズレ)の平均を計算してはいかがでしょうか?
国王:それだと絶対にゼロになるくね?…。
召使:では、平均からの差を2乗した値の平均にしたらどうでしょう?
国王:いいね、採用~!分散と定義しよう。
→分散が爆誕。
後日…
国王:この間の分散だけど、差を2乗した値の平均だから値が大きくて腑に落ちないんだよね…。なんとかなんない?
召使:であれば、分散のルートをとればいい感じになります!
国王:たしかに、ナイスー!じゃあ、標準偏差って名前にしておくね(ヨロ)。
→標準偏差も爆誕
まずは、分散と標準偏差はセットで覚えちゃいましょう!
共分散
2つのデータを混ぜた分散。
共分散は分散と違って、対象となるデータが2つある。「共に」というくらいだからなんとなくイメージできますね。
共分散の求め方ですが、名前が分散と似ていることからも推測できる通り、求め方は結構似てる。
では、共分散の求め方について、今回も具体例でみていこう。
●具体例
Aさん、Bさん、Cさんの国語と数学のテストの点数が下表①のとき、国語と数学の点数の共分散を求めてみよう。
国語と数学でそれぞれ平均を出して(②)、各点数と平均の差を計算(③)します。ここまではデータが2つになっただけで分散の求め方と同じです。
次に、分散であれば平均との差を2乗しましたが、共分散では国語と数学お互いを④のように掛け算して足し算します。たとえば、第1項目であれば、Aさんの「国語の点数」と「数学の点数」の掛け算になります。同じ要領で、第2項目はBさん、第3項目はCさんです。
余談ですが、分散は、共分散の2つのデータが同じ場合(自分自身との共分散)と考えることができます。自分自身とのかけ算なので、平均との差の2乗でよかったわけです。
最後は、平均なのでデータの個数で割ってあげれば共分散になります。
ちなみに、今回みたいに、共分散はマイナスにあることもあります。
・共分散は負になることもある。
散布図
端的に言っちゃえば、たくさんの点が散りばめられた図…なんですが、もう少しちゃんと説明すると、2つのデータを縦軸と横軸に並べたときにその関係性を可視化した図のこと。
散布図では、2つのデータを縦軸と横軸にとることで、お互いの関係性が読み取れます。
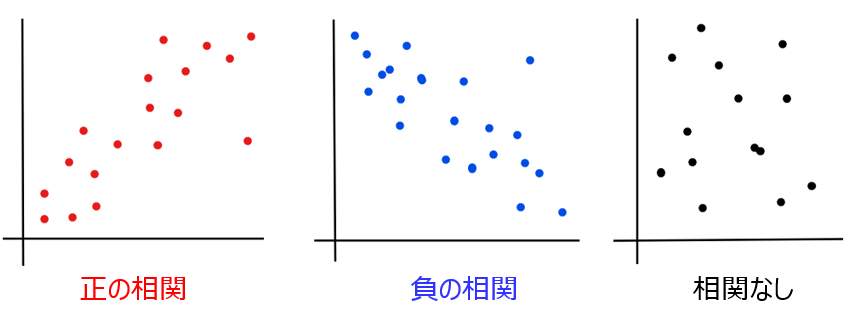
一方が増えると他方も増える関係性を正の相関、一方が増えると他方が減る関係性を負の相関といいます。関係性が見られないものは相関なしといいます。
相関係数
2つのデータの関連度合いを表す値のこと。
計算式はこんな感じ。
●相関係数の公式
~カッコいい版~
$$\small r=\frac{\sigma_{xy}}{\sqrt{\sigma_{x}}\sqrt{\sigma_{y}}}$$
\(\small r\):相関係数、\(\small \sigma_{xy}\):共分散、\(\small \sqrt{\sigma_{x}}、\sqrt{\sigma_{y}}\):標準偏差
~日本語版~
$$\small \displaystyle \mathbf{相関係数}=\frac{x,y\mathbf{の共分散}}{x\mathbf{の標準偏差}\times y\mathbf{の標準偏差}}$$
分かりにくいっすね。でもこの公式は暗記必須です。
せっかく覚えるなら覚えやすい公式がいいですよね?そこでおすすめな覚え方を最後に紹介します。
●相関係数の覚え方(おすすめ)
・共分散をそれぞれの分散のルートで割る
ついでに、もう少しだけ理解を深めると覚えやすくなるかも(多分…)。
●相関係数の豆知識
「係数」は一般的に単位を持たない値を指します。たとえば、日常生活で耳にする言葉だとエンゲル係数とかが有名ですね。
エンゲル係数は、支出に占める食費の割合であり
$$\small \displaystyle \mathbf{エンゲル係数}=\frac{\mathbf{食費(円)}}{\mathbf{支出(円)}}$$
で求められます。ここで、注目してほしいのが、右辺の分母分子が同じ単位(円)になっている点です。なので、左辺のエンゲル係数は単位が約分されて単位を持たない値になります。
では、本題の相関係数に話を戻すと、相関係数も単位を持たない値なので、公式の右辺の分母分子が同じ単位になっている必要があります。
数学では具体的な単位はないので次元という言葉を使いますが、分子が共分散(=分散の次元)なら、分母も分散の次元になっている必要があります。ここで、標準偏差は分散のルートでした。つまり、分母の「\(\small x\)の標準偏差」×「\(\small y\)の標準偏差」は標準偏差の2乗となり分散の次元になります。なので、確かに分母も分子も分散の次元で一致していることが分かります。
ごちゃごちゃ言いましたが、まとめると、分子の共分散が分散みたいなものなので、分子も分散みたいになってないといけないので、それぞれの標準偏差を掛け算していると覚えると忘れにくいかも(私はこれで覚えてます)。
続いて、相関係数で大事なことがもう一つあり、それが相関係数の意味です。
前章で共分散が負になることがあるよ、と言いました。相関係数は分子に共分散があるので、やっぱり相関係数も符号があります。
共分散の具体例で考えると、相関係数は、国語の点数の分散(\(\small\sigma_{x}\))が\(\small 150\)、数学の点数の分散(\(\small\sigma_{y}\))が\(\small \displaystyle \frac{200}{3}\)なので、
\begin{split}
\small r& \small =\frac{-50}{\sqrt{150}\cdot\sqrt{\frac{200}{3}}}\\
& \small =-\frac{50}{5\sqrt{2}\cdot 10\sqrt{2}}\\
& \small =-0.5\\
\end{split}
一般に+0.5以上でやや強い正の相関があり1に近づくほど正の相関が強まります。逆に-0.5以下だとやや強い負の相関があり-1に近づくほど負の相関が強まります。0だと一般には相関なしですが、必ずなしとは言えないので要注意(詳しくは特別講義を参照)。
今回だと、やや強い負の相関(逆相関)があることがわかり、実際に国語と数学の点数を見ると、国語の点数が低いAさんは数学の点数が高く(これ私…)、国語の点数が高いCさんは数学の点数は低めですね。
・一般的に相関係数が負の場合は負の相関、正の場合は正の相関を表す。
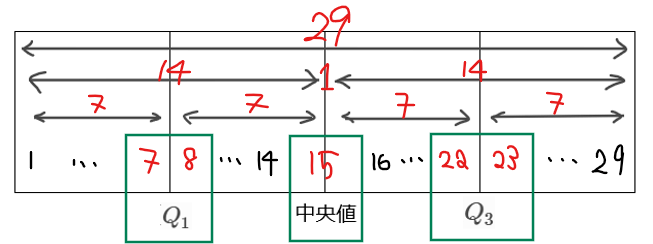
【講義2】四分位数の求め方
四分位数には、第1四分位数、第2四分位数(中央値)、第3四分位数の3つがあります。
四分位数の問題で把握しておくべきことは大きく2つ。1つが各四分位数が何番目のデータか、もう1つが、四分位数の値です。
この2点を把握するときにおすすめの方法が、下図のような箱を書いて求めていく方法です。
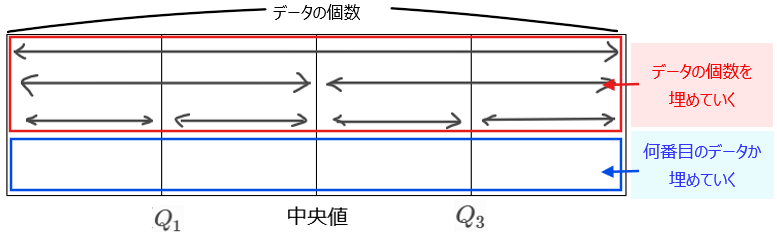
たとえば、全データが30個の場合で、それぞれ四分位数が何番目のデータに該当するのかを求めてみましょう(ちなみに、何番目のデータかまで分かれば、四分位数は簡単に求めることができます)。
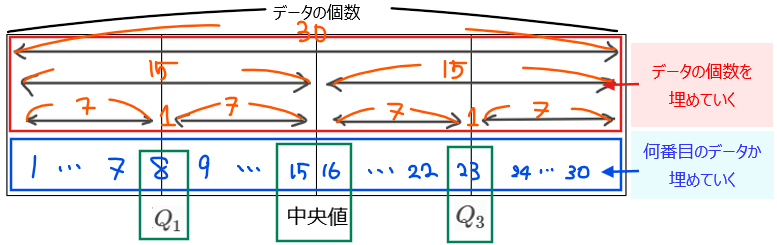
図を上から順番に埋めていくと上記のようになるので、第1四分位数は下位8番目、中央値は下位15番目と16番目の平均値、第3四分位数は下位23番目(または上位8番目)と分かります。
【特別講義】相関係数=ゼロの注意点
相関係数の説明の際に、一般的に0の場合は相関がないといいました。ただ、これはあくまで「一般的に」という点に注意が必要です。
実は、相関係数が0であっても相関がある場合があります。
ここからは実際にどんなパターンがあるのかを問題形式で確認しますが、結構上級者向けの数学になるので、ここまででおなかがいっぱいの人は、相関係数がゼロ≠無相関ということだけ覚えたら飛ばしちゃってもOKです!
相関係数が0の場合であっても、2つのデータに相関がないとは言えないことを示せ。
\(\small \displaystyle \mathsf{相関係数}=\frac{\mathsf{共分散}}{\mathsf{\sqrt{xの分散}\quad \sqrt{yの分散}}}\)ですから、相関係数が0ということは、共分散=0ということです。
共分散は\(\small x、y\)それぞれのデータと平均値の差を掛け算した和だったので、\(\small x、y\)の平均値に対して対称的な形をしたデータ分布であれば相関係数が0になりそうです。
ということで、計算しやすそうな例として以下のような横2列の散布図を考えます。
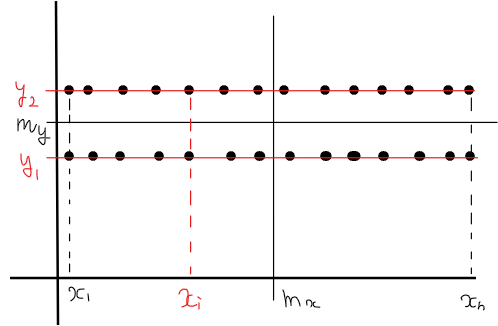
この散布図自体は、各\(\small x\)のデータ\(\small x_i\)に対して、\(\small y\)の値が\(\small y_1\)と\(\small y_2\)の2つずつあるような散布図なので、明らかに2極化しており相関があると言えます。
データの個数は、全部で\(\small 2n\)個で\(\small x\)の平均値を\(\small m_x\)、\(\small y\)の平均値を\(\small m_y\)とします。
まず、相関係数の分母にある\(\small x,y\)それぞれの分散が0ではないことを確認しておきます。
分散の公式から
\begin{split}
\small \sigma_x &\small =\frac{1}{2n}\sum_{i=1}^{n}2(x_i-m_x)^2 \quad \color{red}{ \mathsf{◀上下}2\mathsf{列ずつ同じ値があるため}}\\
& \small = \frac{1}{n}\sum_{i=1}^{n}(x_i-m_x)^2\\
\end{split}
\begin{split}
\small \sigma_y &\small =\frac{1}{2n}\sum_{i=1}^{2n}(y_i-m_y)^2\\
&\small =\frac{1}{2n}\{(y_1-m_y)^2n+(y_2-m_y)^2n\}\\
&\small =\frac{1}{2}\{(y_1-m_y)^2+(y_2-m_y)^2\}\\
\end{split}
となり、いずれも0ではないことが確認できました。
では本題の共分散=0を示していきます。
\begin{split}
\small \sigma_{xy} &\small =\frac{1}{2n}\sum_{i=1}^{n}\{(x_i-m_x)(y_1-m_y)\quad \color{red}{ \mathsf{◀散布図の下の列}}\\
& \small \quad +(x_i-m_x)(y_2-m_y)\}\quad \color{red}{ \mathsf{◀散布図の上の列}}\\
&\small =\frac{1}{2n}\sum_{i=1}^{n}(x_i-m_x)\{(y_1-m_y)+(y_2-m_y)\}\\
&\small =\frac{1}{2n}\sum_{i=1}^{n}(x_i-m_x)\color{red}{(y_1+y_2-2m_y)}\\
\end{split}
ここで、\(\small \displaystyle m_y=\frac{y_1+y_2}{2}\)より、赤字部分は0になるので、和全体としても0。よって、題意は示されました。
今回は証明時の計算のしやすさという観点から横2列の散布図を意図的に選びましたが、他にも以下のような形があります。
本記事のまとめ
今回はヒストグラム、箱ひげ図、散布図の読み取りの問題を中心にデータ分析の総まとめをしていきましたがいかがでしたか?
データ分析で扱われるデータは、普段あまり見慣れない題材が選ばれることもあるため、ぱっと見の雰囲気で難しそうに感じてしまいがちですが、今回の問題からも分かる通り、聞かれていること自体は四分位数や相関係数の意味などの基本的な内容になっています。なので、見た目に惑わされず何を聞かれているのかを読み解く力が重要です。
データ分析の分野は知識自体は簡単なので、入試問題では問題を難しく見せる工夫がされます。そのような問題をしっかり得点するために重要なのは、暗記した知識ではなく、意味まで理解した知識です。
なので、講義1で触れた用語は意味までしっかりと理解しておきましょう。
それでは、今回はここまです。お疲れさまでした!


コメント